Trumpas įrašas apie duomenų saugojimą ir įrankį kurį naudoju peržiūrai. Ankstesniuose įrašuose minėjau, kad tikrai nepulsiu visko iš eilės automatizuoti. Viskas turi būti pamatuota, panalizuota, gal net išsibandyta mažesniu mastu. Bet reikia turėti ką analizuoti, tai trumpai apie duomenų kaupimą. OpenHAB iš savęs sudaro neblogas sąlygas kaupti duomenis net standartinėj instaliacijoje. Nekeitus jokių nustatymų duomenis iš visokių jungiklių ir sensorių kažkiek kaupia naudojant vidinį mechanizmą (berods į JSON failus rašo) ir paskui paišo grafikiukus. Vienok gerai jei tik OpenHAB naudojamas, bet jei norima tuos duomenis pasijungt ant kitų įrankių – problema. Natūralu, kad reikia kažkokios duombazės.
Renkamės duombazę
Jei kažkas mėgsta sado-mazo, tai aišku visada galima rinktis daug kam pažįstamą MySQL. Jei kažkas turi fetišą Microsofto produktams – Microsoft SQL Server. Dar gyvas velnias tų reliacinių duombazių yra blė. Visgi tokio tipo duomenims yra išrastos „Timeseries” duombazės. Pamenu, kad duombazę išsirinkau įvedęs į google „best timeseries opensource database”. Tai taip jau gavosi, kad tuo metu buvo du favoritai internetuose TimescaleDB ir InfluxDB. Pasižiūrėjau palyginimus ir pasirinkau InfluxDB.
InfluxDB
Daug ko pasakot nėra apie šią duombazę. NoSQL tipo duombazė, bet palaiko SQL-like kalbą formuoti užklausoms. Be jokių plugin’ų palaikoma Grafanos.
Aišku kad viską leidžiam konteineryje
Detaliau apie konteinerizaciją čia.
version: '2.0'
services:
influxdb:
image: influxdb:1.8.3
container_name: influxdb
ports:
- 8086:8086
volumes:
- ./influxdb:/var/lib/influxdb
- "/etc/timezone:/etc/timezone:ro"
- "/etc/localtime:/etc/localtime:ro"
environment:
INFLUXDB_DB: openhab
INFLUXDB_ADMIN_ENABLED: 'true'
INFLUXDB_ADMIN_USER: kažkoks_admino_useris
INFLUXDB_ADMIN_PASSWORD: Kažkoks_pass
INFLUXDB_USER: useris_be_admin_teisių
INFLUXDB_USER_PASSWORD: jo_password
restart: always
Tokią rašliavą susidedam į tą patį docker-compose failą kur openHAB ar bet kas kitas kam reik tos duombazės. Paleidžiam su docker-compose up -d ir viskas. Nieko siųstis nereikia – viską atsiųs ir paleis. Hostname bus influxdb, arba tiesiog localhost jei ne iš konteinerio bandant pasiekt.
OpenHAB konfiguracija
Įsirašom InfluxDB persistance pluginą. Pagal instrukciją sukonfiguruojam openhab_conf/services/influxdb.cfg failą. Prie persistance nustatymų pasirenkam InfluxDB. Ir bazinis konfigūravimas baigtas.
Saugom viską!
Jei gerai pamenu su „default” plugino nustatymais į influx’ą niekas nesaugojama iš OpenHAB. Reikia sukonfiguruoti openhab_conf/persistence/influxdb.persist failą. Ten galima apsirašyti taisykles, kokius „items (openHAB terminologija)” saugoti į duombazę, ko ne. Mano požiūris, kad saugosim viską. Tai yra kiekvieną pirstelėjimą, nesvarbu ar jis naudingas ar ne. Nes vėliau tų duomenų neišgeneruosiu jei sugalvosiu kad reikia, arba užtruks kol surinksiu. Mano failas atrodo taip:
Strategies {
everyMinute : "0 * * * * ?"
everyHour : "0 0 * * * ?"
everyDay : "0 0 0 * * ?"
default = everyChange
}
Items {
* : strategy = everyChange, everyHour, restoreOnStartup
}
Čia šiokia tokia optimizacija padaryta, kad jei kažkokia reikšmė nesikeičia tai nedrožia duombazės ir įrašo tik kas valandą.
Reiktų dar paoptimizuoti truputį, nes pvz rekuperatoriaus temperatūrų grafikai labai triukšmingi (kurią rekuperatoriaus gražinamą temperatūrą paimsi – visos tokios) ir prigeneruoja krūvą nereikalingos info (vis neprieina rankos susitvarkyt):
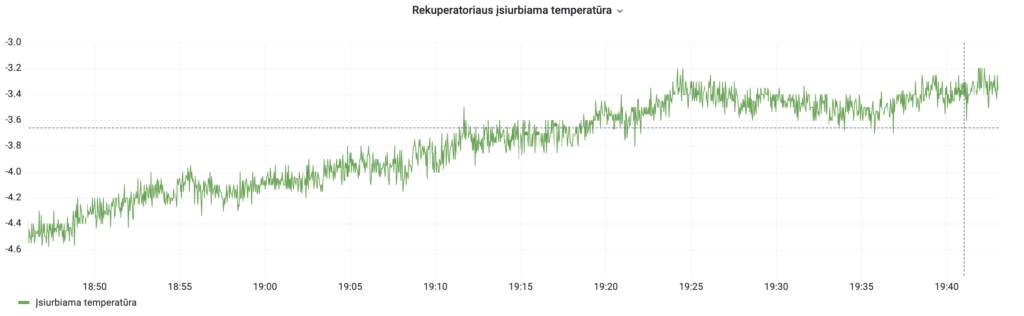
Visas gerumas šito plugino, o gal ir apskritai openHAB, kad vos naują daiktą pridedu į openHAB, automatiškai jį pradeda į duombazę įrašinėti – jokio rankinio darbo. Kitaip tariant vieną kart nustatei ir pamiršai.
Įdomioji statistika
Šiai dienai saugomi 68 skirtingi namo parametrai. Čia tiek šviestuvų įjungimo laikai, dimeriavimo reikšmės, tiek visokios temperatūros, drėgmės, rekuperatoriaus ar dujų katilo parametrai. Kaip kokius duomenis susirenku, aprašysiu kituose įrašuose.
Kaupimas vyksta virš metų, tai šiai dienai prikaupta 800MB+ duomenų.
Analizė
Analizei vienas iš geresnių įrankų – grafana. Dockerio konteinerio docker-compose:
version: '2.0'
services:
grafana:
image: grafana/grafana:9.1.2
user: "1000"
container_name: grafana
ports:
- 3000:3000
volumes:
- ./grafana:/var/lib/grafana
restart: always
O pasileidus su Grafana jau galima paišytis ir dėliotis kiek fantazija leidžia:
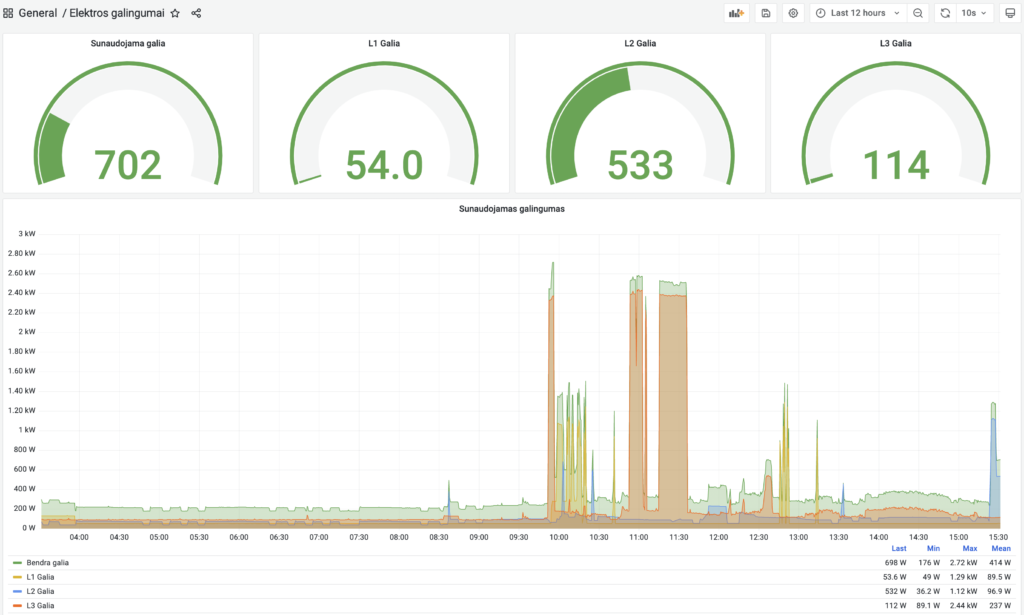
Jei trūksta grafanos pajėgumų ir norisi kokį AI analizę paleist, nėra sunku tuos duomenis ir per kokį Python pasiimti.
Pabaigai
Visas įgyvendinimas jau gerokai pažengęs nuo to ką aprašau, bet tiesiog, visko aprašymui nėra tiek laiko.
1 Atgalinis pranešimas: